Ted Dziuba has penned a humorous and sharp-tongued piece for The Register about last week’s Adblock vs. NoScript fiasco. For those of you who aren’t Firefox junkies, a nasty public spat broke out between the makers of these two very popular Firefox Browser extensions (they are the #1 and #3 most popular downloads respectively). To make a long and complicated story much shorter, basically, NoScript didn’t like Adblock placing them on their list of blacklisted sites and so they fought back by tinkering with the NoScript code to evade the prohibition. Adblock responded by further tinkering with their code to circumvent the circumvention! And then, as they say, words were exchanged.
Thus, a war of words and code took place. In the end, however, it had a (generally) happy ending with NoScript backing down and apologizing. Regardless, Mr. Dzuiba doesn’t like the way things played out:
The real cause of this dispute is something I like to call Nerd Law. Nerd Law is some policy that can only be enforced by a piece of code, a public standard, or terms of service. For example, under no circumstances will a police officer throw you to the ground and introduce you to his friend the Tazer if you crawl a website and disrespect the robots.txt file.
The only way to adjudicate Nerd Law is to write about a transgression on your blog and hope that it gets to the front page of Digg. Nerd Law is the result of the pathological introversion software engineers carry around with them, being too afraid of confrontation after that one time in high school when you stood up to a jock and ended up getting your ass kicked.
Dziuba goes on to suggest that “If you actually talk to people, network, and make agreements, you’ll find that most are reasonable” and, therefore, this confrontation and resulting public fight could have been avoided. They “could have come to a mutually-agreeable solution,” he says.
But no. Sadly, software engineers will do what they were raised to do. And while it may be a really big hullabaloo to a very small subset of people who Twitter and blog their every thought as if anybody cared, to the rest of us, it just reaffirms our knowledge that it’s easy to exploit your average introvert. After all, what’s he gonna do? Blog about it?
OK, so maybe the developers could have come to some sort of an agreement if they had opened direct channels of communications or, better yet, if someone at the Mozilla Foundation could have intervened early on and mediated the dispute. At the end of the day, however, that did not happen and a public “Nerd War” ensued. But I’d like to say a word in defense of Nerd Law and public fights about “a piece of code, a public standard, or terms of service.”
Continue reading →
 Come one, come all. ACT will be hosting a lunch event next Tuesday (June 23) at noon on privacy, free software, and government procurement.
Come one, come all. ACT will be hosting a lunch event next Tuesday (June 23) at noon on privacy, free software, and government procurement.
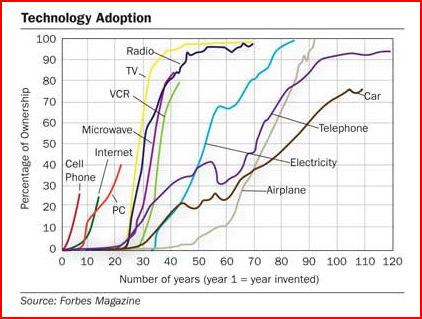
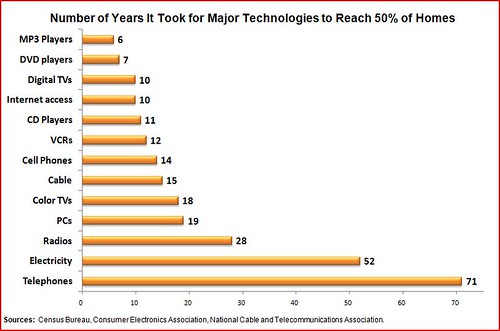
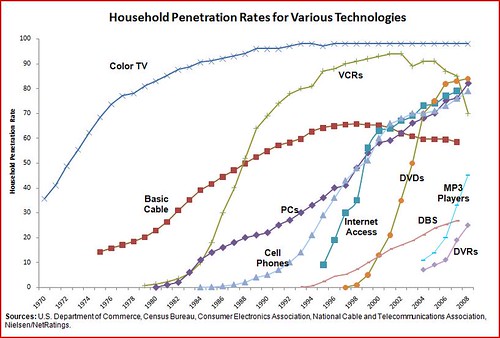
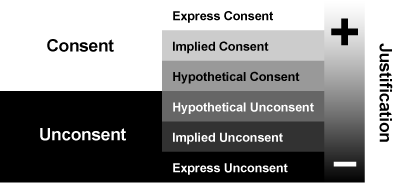
 The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.