As a means of introducing myself to TLF readers, this is an article that I wrote for the PFF blog in September that has not been previously mentioned on the TLF. Most of my other PFF blog posts have been cross-posted by Adam Thierer or Berin Szoka, but I’ve taken ownership of those posts so they appear on my TLF author page.
This is the first in a series of articles that will focus directly on technology instead of technology policy. With an average age of 57, most members of Congress were at least 30 when the IBM PC was introduced in 1981. So it is not surprising that lawmakers have difficulty with cutting-edge technology. The goal of this series is to provide a solid technical foundation for the policy debates that new technologies often trigger. No prior knowledge of the technologies involved is assumed, but no insult to the reader’s intelligence is intended.
This article focuses on cookies–not the cookies you eat, but the cookies associated with browsing the World Wide Web. There has been public concern over the privacy implications of cookies since they were first developed. But to understand them , you must know a bit of history.
According to Tim Berners Lee, the creator of the World Wide Web, “[g]etting people to put data on the Web often was a question of getting them to change perspective, from thinking of the user’s access to it not as interaction with, say, an online library system, but as navigation th[r]ough a set of virtual pages in some abstract space. In this concept, users could bookmark any place and return to it, and could make links into any place from another document. This would give a feeling of persistence, of an ongoing existence, to each page.”[1. Tim Berners-Lee, Weaving The Web: The Original Design and Ultimate Destiny of the World Wide Web. p. 37. Harper Business (2000).] The Web has changed quite a bit since the early 1990s.
Today, websites are much more dynamic and interactive, with every page being customized for each user. Such customization could include automatically selecting the appropriate language for the user based on where they’re located, displaying only content that has been added since the last time the user visited the site, remembering a user who wants to stay logged into a site from a particular computer, or keeping track of items in a virtual shopping cart. These features are simply not possible without the ability for a website to distinguish one user from another and to remember a user as they navigate from one page to another. Today, in the Web 2.0 era, instead of Web pages having persistence (as Berners-Lee described), we have dynamic pages and “user-persistence.”
This paper describes the various methods websites can use to enable user-persistence and how this affects user privacy. But the first thing the reader must realize is that the Web was not initially designed to be interactive; indeed, as the quote above shows, the goal was the exact opposite. Yet interactivity is critical to many of the things we all take for granted about web content and services today.
Continue reading →
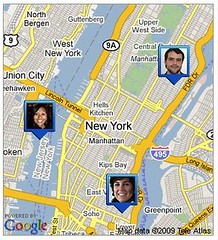 Google’s latest major launch is “Latitude,” a geo-location service that lets users find friends on a digital map and then network with them. These services are often referred to as “LBS,” which stands for “location-based services.” I wrote about LBS here before in my essay on “The Next Great Technopanic: Wireless Geo-Location / Social Mapping.” As I pointed out in that piece, LBS raise privacy concerns with some people because, by their nature, these technologies involve the tracking of users.
Google’s latest major launch is “Latitude,” a geo-location service that lets users find friends on a digital map and then network with them. These services are often referred to as “LBS,” which stands for “location-based services.” I wrote about LBS here before in my essay on “The Next Great Technopanic: Wireless Geo-Location / Social Mapping.” As I pointed out in that piece, LBS raise privacy concerns with some people because, by their nature, these technologies involve the tracking of users.
 business—the placement of “contextually targeted” ads next to search engine results based on the search terms that produced those results.
business—the placement of “contextually targeted” ads next to search engine results based on the search terms that produced those results. The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.