 In his latest Slate column, Tim Wu endorses a modified Google Books Search settlement because he fears that without such a deal–through which a giant like Google gets a de facto monopoly–we will never see an online library that includes orphan works and out-of-print books. He writes:
In his latest Slate column, Tim Wu endorses a modified Google Books Search settlement because he fears that without such a deal–through which a giant like Google gets a de facto monopoly–we will never see an online library that includes orphan works and out-of-print books. He writes:
Books in strong demand, whether old (Dracula) or contemporary (Never Let Me Go), are in print and available no matter what happens. … The Google Book Search settlement makes it easier to get books few people want, like the Windows 95 Quick Reference Guide, whose current Amazon sales rank is 7,811,396, or The Wired Nation, which in 1972 predicted a utopian age centered on cable television. These are titles of enormous value for research and that appeal to a certain type of obsessive. Yet they are also unlikely to be worth much money.
And this, I hope, makes clear my point. A delivery system for books that few people want is not a business one builds for financial reasons. Over history, such projects are usually built not by the market but by mad emperors. No bean counter would have approved the Library of Alexandria or the Taj Mahal.
I’m curious how Prof. Wu can square that with what he wrote in his Slate review of Chris Anderson’s The Long Tail in 2006:
The products in the Long Tail are less popular in a mass sense, but still popular in a niche sense. What that means is that some businesses, like Amazon and Google, can make money not just on big hits, but by eating the Long Tail. They can live like a blue whale, growing fat by eating millions of tiny shrimp. …
What are the Long Tail’s limits? As a business model, it matters most 1) where the price of carrying additional inventory approaches zero and 2) where consumers have strong and heterogeneous preferences. When these two conditions are satisfied, a company can radically enlarge its inventory and make money raking in the niche demand. This is the lifeblood of a handful of products and companies, Apple’s iTunes, Netflix, and Google among them, all of which are basically in the business of aggregating content. It doesn’t cost much to add another song to iTunes—having 10,000 songs available costs about the same as having 1 million. Moreover, people’s music preferences are intense—fans of Tchaikovsky aren’t usually into Lordi.
Scanning books is expensive, but not so expensive that we need the government or a regulated utility provider (as Wu suggests) to do it. If a fair use exemption or other workaround was available, I’m sure we’d see more than one competitor jump into the space. Like Prof. Wu understood in 2006, and as Google knows now, there is lots of money to be made in hyper-narrow niches.
Cross-posted from Surprisingly Free. Leave a comment on the original article.
Tomorrow, Friday, Oct. 2, the Information Economy Project at the George Mason University School of Law will hold a conference on Michael Heller’s new book The Gridlock Economy. Surprisingly Free will be streaming live video of the the conference kick-off debate between Heller and Richard Epstein at 8:30 a.m. (It will also be available for download later for folks allergic to early mornings.)
Called “Tragedies of the Gridlock Economy: How Mis-Configuring Property Rights Stymies Social Efficiency,” the conference will
explore a paradox that broadly affects the Information Economy. Property rights are essential to avoid a tragedy of the commons; defined properly, such institutions yield productive incentives for creation, conservation, discovery and cooperation. Applied improperly, however, such rights can produce confusion, wasteful rent-seeking, and a tragedy of the anti-commons.
This conference, building on Columbia University law professor Michael Heller’s book, The Gridlock Economy, tackles these themes through the lens of three distinct subjects: “patent thickets,” reallocation of the TV band, and the Google Books copyright litigation.
In the meantime, check out this video of Michael Heller at Google giving his elevator pitch.
http://www.youtube.com/v/9n89Ec3DFtk&hl=en&fs=1&
 This week Google unveiled Sidewiki, a tool that lets users annotate any page on the web and read other users’ notes about the page they are visiting. Professional Google watcher Jeff Jarvis quickly panned the service saying that it bifurcates the conversation at sites that already have commenting systems, and that it relieves the site owner of the ability to moderate. Others have pooh-poohed the service, too.
This week Google unveiled Sidewiki, a tool that lets users annotate any page on the web and read other users’ notes about the page they are visiting. Professional Google watcher Jeff Jarvis quickly panned the service saying that it bifurcates the conversation at sites that already have commenting systems, and that it relieves the site owner of the ability to moderate. Others have pooh-poohed the service, too.
What strikes me about the uproar is that Sidewiki is a lot like the “electronic sidewalks” that Cass Sunstein proposed in his book Republic.com. The concept was first developed in detail in a law review article by Noah D. Zatz titled, Sidewalks in Cyberspace: Making Space for Public Forums in the Electronic Environment [PDF]. The idea is a fairness doctrine for the Internet that would require site owners to give equal time to opposing political views. Sunstein eventually abandoned the view, admitting that it was unworkable and probably unconstitutional. Now here comes Google, a corporation, not the government, and makes digital sidewalks real.
The very existence of Sidewiki, along with the fact that anyone can start a blog for free in a matter of minutes, explodes the need for a web fairness doctrine. But since we’re not talking about government forcing site owners to host opposing views, I wonder if we’re better off with such infrastructure. As some have noted, Google is not the first to try to enable web annotation, and the rest have largely failed, but Google is certainly the biggest to make the attempt. As a site owner I might be worse off with Sidewiki content next to my site that I can’t control. But as a consumer of information I can certainly see the appeal of having ready access to opposing views about what I’m reading. What costs am I overlooking? That Google owns the Sidewiki-sidewalk?
Cross-posted from Surprisingly Free. Leave a comment on the original article.
One of the projects I run is OpenRegs.com, an alternative interface to the federal government’s official Regulations.gov site. With the help of Peter Snyder, we recently developed an iPhone app that would put the Federal Register in your pocket. We duly submitted it to Apple over a week ago, and just received a message letting us know that the app has been rejected.
 The reason? Our app “uses a standard Action button for an action which is not its intended purpose.” The action button looks like the icon to the right.
The reason? Our app “uses a standard Action button for an action which is not its intended purpose.” The action button looks like the icon to the right.
According to Apple’s Human Interface Guidelines, its purpose is to “open an action sheet that allows users to take an application-specific action.” We used it to bring up a view from which a user could email a particular federal regulation. Instead, we should have used an envelope icon or something similar. Sounds like an incredibly fastidious reason to reject an application, right? It is, and I’m glad they can do so.
Continue reading →
 TLF friends, I have an announcement: Today the Mercatus Center at George Mason University is launching a new Technology Policy Program, which I will be directing. Perhaps more exciting for TLF readers, though, is that we’re also launching a new blog and podcast.
TLF friends, I have an announcement: Today the Mercatus Center at George Mason University is launching a new Technology Policy Program, which I will be directing. Perhaps more exciting for TLF readers, though, is that we’re also launching a new blog and podcast.
The new site is called Surprisingly Free, and it will focus on the intersection of technology, policy, and economics. We’ll feature commentary from Mercatus and GMU scholars, guest bloggers, and aggregated posts from other academics around the country.
The podcast is imaginatively called Surprisingly Free Conversations and it’s modeled after Russ Robert’s excellent Econtalk. The format is a weekly in-depth one-on-one conversation with a thinker or entrepreneur in the tech field. The first episode is up and features TLF veteran Tim Lee on bottom-up processes, innovation, and the future of news. Check it out, and please subscribe in iTunes.
We’re looking forward to engaging the tech policy discussion online from a law and econ academic perspective, and we hope you’ll join us for the ride. I look forward to your feedback!
The FCC announced today that it will consider adopting net neutrality rules. The announcement comes in a speech by Chairman Julies Genachowski, which you can read here and watch here. Genachowski says,
To date, the Federal Communications Commission has addressed these issues by announcing four Internet principles that guide our case-by-case enforcement of the communications laws. … The principles were initially articulated by Chairman Michael Powell in 2004 as the “Four Freedoms,” and later endorsed in a unanimous 2005 policy statement[.] … Today, I propose that the FCC adopt the existing principles as Commission rules, along with two additional principles that reflect the evolution of the Internet and that are essential to ensuring its continued openness.
By suggesting that they must be codified, Genachowski is implicitly (if not explicitly) conceding that the FCC’s Internet principles are a mere policy statement and not a binding and enforceable rule. I’ve explained why this is the case previously. So, someone should call the D.C. Circuit, considering the Comcast case, and let them know their job just got a lot easier.
Second, Genachowski gives “limited competition” as a reason to consider regulation. However, the best available data from the FCC show that 98% of zip codes have 2 or more broadband providers, 88% of zip codes have 4 or more broadband providers, and 77% of zip codes have 5 or more broadband providers. That said, some have questioned whether the FCC’s data are accurate, and the FCC’s next broadband report is supposed to have data gathered at the census tract level for a more detailed set of speed categories. So, the FCC is proposing a regulation before it has completed an ongoing study to discover whether there is a real problem. It’s almost as if Kevin Martin is still running the place.
If you’re a lawyer, and you use the crazy-outmoded PACER system to access federal court documents, check out the new RECAP system launched today by Tim Lee, Harlan Yu, and Steve Schultze with the help of Princeton’s CITP. If you use PACER, you know it’s difficult to use. It also charges citizens to access what are nominally public documents, something that makes little sense online. This combination has resulted in a multi-million dollar surplus for the judiciary’s IT department, and lousy access to data that would be useful not just to lawyers and litigants, but to bloggers, librarians, reporters, and scholars.
Schultze, Lee, and Yu’s scheme to free the documents on PACER is an ingenious one. They have built a Firefox plugin called RECAP that attorneys and other regular users of PACER can install on their computers. When a user downloads a document from PACER, the plugin sends a copy to RECAP’s server, where it is made publicly available. If enough PACER users install RECAP, it will only be a matter of time before the entire database is liberated. Why would lawyers participate? When they search for a document, the plugin first checks the RECAP database to see if a copy has already been liberated. If it has, then the lawyer can retreive it without paying PACER. Like I said: ingenious.
I’m happy to see so many folks take up Carl Malamud’s mantle and not only liberate government data, but also provide competition to government. It’s the impetus behind my own OpenRegs.com. By demonstrating what’s possible, how the world won’t end when data is made freely available, we create demand for change in government. Three cheers for RECAP! Continue reading →
One reason AT&T may not like Google Voice is that it allows you to send and receive text messages for free. This has led many to argue that SMS are free to the carriers and they are overcharging. Congress is considering getting involved. Most recently there’s this from David Pogue in the NY Times:
The whole thing is especially galling since text messages are pure profit for the cell carriers. Text messaging itself was invented when a researcher found “free capacity on the system” in an underused secondary cellphone channel: http://bit.ly/QxtBt. They may cost you and the recipient 20 cents each, but they cost the carriers pretty much zip.
The price of a text message does sound ridiculous when you consider it on a per bit basis. The problem with thinking about it that way, though, is that it neglects the fact that AT&T had to build a network, and it has to maintain that network, before a text message can be “free.” AT&T charges customers so it can recoup its investment. It does so through voice and data service fees, but also through other fees, including for text messages. However it charges customers, it ultimately has to bring in enough to cover its costs or it goes out of business.
Now, if we passed a law today that said carriers could not charge for SMS because, after all, it’s free, we would see a an increase in the fees it charges for voice, data, and other services. The mix of prices for services we have right now is one the market will bear and consumers want, and there’s no reason to think that we could command a better one.
Better yet, if you want a “free” text messaging option, consider Boost Mobile, which offers just that. Of course, they have different voice prices and an older and slower network. In the end, they have to cover their costs, too.
Any time I’ve heard government officials talk about the future of Recovery.gov, I’ve heard them mention maps. Maps that will let you drill down to your neighborhood and see the stimulus spending right around you. Well, the maps were rolled out last Thursday, and there was even a congratulatory press release from Vice President Biden. Tell me if you notice anything interesting in this map of federal grant recipients from Recovery.gov.
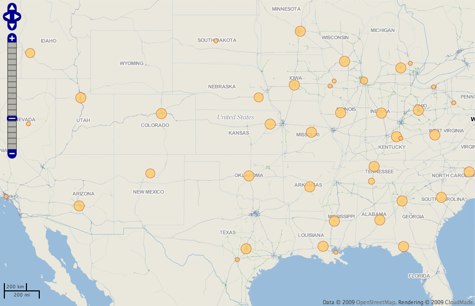
Geography wizzes will recognize that almost all the bubbles on the map, which represent federal grants, neatly coincide with state capitals. Check it out for yourself right here. What this highlights is a deeper problem of stimulus spending data: reporting is only required to go to two levels down. Sure, we can see that the Department of Education gave the state of California (displayed on the map as a bubble in Sacramento) so many millions of grant dollars. And we may even know that California gave a subgrant to the Los Angeles School Board. But what happens after that is missing, and will likely remain missing under the Act’s transparency requirements and OMB guidance.
These maps are great, but I’d rather have deep, meaningful data in a structured format so I can make my own maps.
Evgeny Morozov has an op-ed in the New York Times today that makes the case that cyberattacks are not an existential threat to the country or anything even close. He also argues that more secrecy around cybersecurity is exactly the wrong way to address the problem, citing the old geek adage “given enough eyeballs, all bugs are shallow.” He even explains that “Much of the real computer talent today is concentrated in the private sector,” and that “It’s no secret that many computer science graduates perceive government jobs as an ‘IT ghetto.'”
So far so good. Bravo, in fact. Unfortunately, he suggests that “To inject more talent into government IT jobs, it is necessary to raise their visibility and prestige, perhaps by creating national Tech Corps that could introduce talent into sectors that need it most.”
As Jim Harper has noted, given that cyberattacks may not be as serious a threat as many assume, it might be better to allow the private sector (which has the talent and the incentive) to protect its own infrastructure. DHS and the military can protect the .govs and the military the .mils. The government could benefit from private R&D on run-of-the-mill cybersecurity, and they can focus on protecting critical and secret assets, which in any case should not be connected directly to the wider internet.

 The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.