Ok, I didn’t say anything last month when Jerry—albeit with some caveats—cited that FCC stat about how 88 percent of zip codes have four or more broadband providers. But now I see my friend Peter Suderman relying on the same figure over at Reason. And friends don’t let friends use FCC broadband data.
First, since a zip code is considered to be “served” by a provider if it has a single subscriber in that area, this is not a terribly helpful measure of competition, which is a function of what you can get at any given
household. More importantly, the definition of “broadband” here is a blazing 200 Kbps unidirectional—or about 1/20th the average broadband connection speed in the U.K., itself the slowpoke of Europe. A third of the connections they’re calling “broadband” don’t even reach that pathetic speed bidirectional. Of the 2/3 that do manage to reach that speed both ways, almost half are slower than 2.5 Mbps in the faster direction.
Mobile companies are by far the most common “broadband” providers in their sample, with “at least some presence” in 99% of their zip codes, so
at least one of those four providers is almost certainly a mobile company. It’s probably a lot more than that: In only 63% of zip codes were both cable and ADSL subscribers reported—and remember, that doesn’t even tell us whether any households actually had even the choice between a cable and an ADSL provider. So we can see how easily you get to four providers under this scheme: You just have to live in a zip code with, let’s say, an incumbent cable company offering what passes for “real” broadband in the U.S., plus even spotty coverage under a 3G network (average downstream speed 901–1,940 Kbps, depending on your provider) , and a couple of conventional cellular carriers with Edge or EVDO coverage that just squeaks over the 200 Kbps bar. Congratulations, you’re a lucky beneficiary of U.S. “broadband competition.” Woo.
Look, I think the average person in this country understand that their broadband options are pretty crap, and there’s not much percentage in telling them to ignore their lying eyes and check out some dubious numbers. If the argument against net neutrality depends on the idea that we currently have robust competition in real broadband, well, the argument is in a lot of trouble. What I find much more compelling is the idea that, with 4G rollouts on the horizon, we may actually
get adequate broadband competition in the near-to-medium term, and might want to be wary about rushing into regulatory solutions that not only assume the status quo, but could plausibly help entrench it.
Addendum: That Pew survey I cited in the previous post did ask individual home broadband subscribers how many providers they had to choose from. Obviously, that sample excludes people without any broadband access, but 21% (and 30% of rural users) said they only had a single provider, and only a quarter of those who had multiple providers said they had as many as four. Since average prices appeared to be lower the more competition was present, and assuming ceteris paribus you get higher adoption when prices are lower, this sounds likely to overstate the actual degree of choice Americans enjoy.


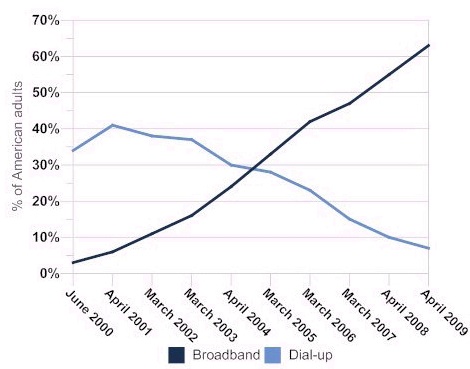 One reason might be that it’s hard to imagine the growth curve for Internet adoption being a whole lot steeper than it is. According to
One reason might be that it’s hard to imagine the growth curve for Internet adoption being a whole lot steeper than it is. According to  The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.