 Google’s latest major launch is “Latitude,” a geo-location service that lets users find friends on a digital map and then network with them. These services are often referred to as “LBS,” which stands for “location-based services.” I wrote about LBS here before in my essay on “The Next Great Technopanic: Wireless Geo-Location / Social Mapping.” As I pointed out in that piece, LBS raise privacy concerns with some people because, by their nature, these technologies involve the tracking of users.
Google’s latest major launch is “Latitude,” a geo-location service that lets users find friends on a digital map and then network with them. These services are often referred to as “LBS,” which stands for “location-based services.” I wrote about LBS here before in my essay on “The Next Great Technopanic: Wireless Geo-Location / Social Mapping.” As I pointed out in that piece, LBS raise privacy concerns with some people because, by their nature, these technologies involve the tracking of users.
But I’ve argued that those concerns are generally over-blown, especially because you have to download and opt-in to these services. In other words, you know what you’re getting into. Moreover, companies who offer these services, like Loopt and now Google, go out of their way to offer privacy safeguards. Indeed, even some privacy activists agree.
For example, Michael Zimmer of the School of Information Studies at the University of Wisconsin-Milwaukee, is someone who pays close attention to privacy issues and is often critical of Google and other companies for supposedly not paying enough attention to privacy concerns. In the case of Latitude, however, he argues that “Google Actually Got it (Mostly) Right.” Here’s his snapshot of “what Google’s done to help give users control of their information flows in Latitude”:
Continue reading →
 I finally got around to reading Planet Google: One Company’s Audacious Plan to Organize Everything We Know, by Randall Stross. It’s very well done. Stross is a frequently contributor to the New York Times and the author of several other interesting books on the technology industry. He knows how to weave a story together, and it helps that Google’s story is a pretty amazing one.
I finally got around to reading Planet Google: One Company’s Audacious Plan to Organize Everything We Know, by Randall Stross. It’s very well done. Stross is a frequently contributor to the New York Times and the author of several other interesting books on the technology industry. He knows how to weave a story together, and it helps that Google’s story is a pretty amazing one.
Each chapter discusses a different part of Google’s growing family of services — GMail, Google Maps, Google Earth, Book Search, and YouTube. Of course, it all started with search and Stross does a good job explaining how the ingenious Google search algorithm has grown from dorm room project to the greatest aggregator of human knowledge that the world has ever known. This, in turn, has powered Google’s hugely successful online advertising system. The real secret of their success with online advertising, Stross argues, is that “Google’s impersonal, mathematical approach search also provides you with the ability to serve advertisements that are tailored to a search, rather than to the person submitting the search request, whose identity would have to be known.”
Despite the benefits of such generally anonymous searching, as Google has grown and added new services and capabilities, concerns about the sheer volume of data that the company collects have led to heightened privacy concerns. Indeed, privacy is a core theme that Stross uses in the book to tie many of the chapters and issues together. Google is constantly struggling to strike the right balance between providing more access to the world’s information while also being careful not to raise privacy concerns. But it’s unclear exactly how much more information collection that users (or public officials) will tolerate before advocating stricter limits on Google’s reach. As Stross points out:
Guided by its founding mission, to organize all the world’s information, Google has created storage capacity that allows it to gain control of what its users are you doing in a comprehensive way that no other company has done, and to preserve those records indefinitely, without the need to clear out old records to make way for new ones. Moreover, Google differentiates its service by refining its own proprietary software formula to mine and massage the data, technology that it zealously protects from the sight of rivals. This sets up a conflict between Google’s wish to operate a “black box” (completely opaque to the outside) and its users’ wish for transparency.
Continue reading →
[This represents a bit of a departure from the traditional format of my ongoing “Media Deconsolidiation Series,” but you will see how it ties in…]
So, some guy from the (Un)Free Press — the activist group that wants to regulate every facet of the media and broadband universe — has created a scary looking chart about “Information Control” [seen below]. It’s based loosely on the Periodic Table of Elements, you know, to give it the aura of science and fact. In reality, it’s just another silly scare tactic that tells us very little about the true nature of our modern media marketplace.
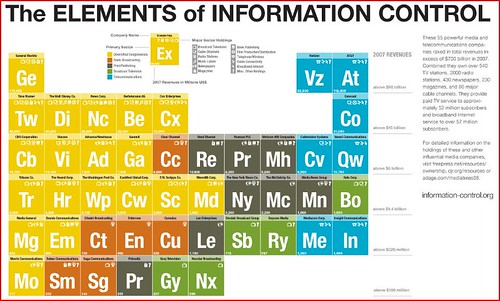
The chart is accompanied by the typical Free Press gloom-and-doom rhetoric about the unfolding media apocalypse. “Nearly everything you see, hear and read that isn’t from a friend — whether on TV, the radio, or even on the Web — comes from a for-profit gatekeeper.” And then comes the obligatory A.J. Liebling quote about how “Freedom of the press belongs to those who own one,” followed quickly by the typical punch line about how just a handful of companies (in this case 55 of ’em) are puppeteering all our thoughts in America today:
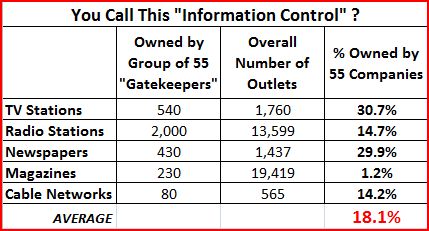
Combined, these 55 powerful media and telecommunications companies raked in total revenues in excess of $700 billion in 2007. Together they own over 540 TV stations, 2000 radio stations, 430 newspapers, 230 magazines, and 80 major cable channels in the United States. They provide paid TV service to approximately 52 million subscribers and broadband Internet service to over 57 million subscribers. They’re the bottlenecks through which our news, our entertainment, and our political discourse must travel. What they want to promote becomes prominent; what they suppress stays out of the mainstream. As such, these companies are the elements of information control.
Oh my God! We are all just brainwashed sheep!
Except we’re not. It amazes me how these “information control” and “media monopoly” myths keep getting widespread circulation. But the first thing to note is how the media reformistas can’t get even their story straight when it comes to how many “monopolists” are supposedly out there today. As I noted in my 2005 book, Media Myths: Making Sense of the Debate over Media Ownership, the critics seem to just pull their numbers out of a hat. Some say as few as 3 companies control everything. Others says 5 or 6. Still others say it might be a few dozen. And now this guy says its 55. Hey, that’s progress that even the Free Press should love!
Regardless of the number, does this really represent the totality of our modern media universe? Do those 55 companies really “own most of the 21st-century presses in America” as the “Info Control” website states? Answer: NOT. EVEN. CLOSE. Here are the facts. [I happened to have compiled them for a PFF special report entitled Media Metrics: The True State of the Modern Media Marketplace to debunk myths just like this.]
Continue reading →
 With the publication of Understanding Privacy (Harvard University Press 2008), George Washington University Law School professor Daniel J. Solove has firmly established himself as one of America’s leading intellectuals in the field of information policy and cyberlaw. Solove had already made himself a force to be reckoned with in this field with the publication of important books like The Future of Reputation: Gossip, Rumor, and Privacy on the Internet (Yale University Press 2007), The Digital Person: Technology and Privacy in the Information Age (NYU Press 2004) and his treatise on Information Privacy Law with Paul M. Schwartz of the Berkeley School of Law (Aspen Publishing, 2d ed. 2006). But with Understanding Privacy, Solove has now elevated himself to that rarefied air of “people worth watching” in the cyberlaw field; an intellectual — like Lawrence Lessig or Jonathan Zittrain — whose every publication becomes something of an event in the field to which all eyes turn upon release.
With the publication of Understanding Privacy (Harvard University Press 2008), George Washington University Law School professor Daniel J. Solove has firmly established himself as one of America’s leading intellectuals in the field of information policy and cyberlaw. Solove had already made himself a force to be reckoned with in this field with the publication of important books like The Future of Reputation: Gossip, Rumor, and Privacy on the Internet (Yale University Press 2007), The Digital Person: Technology and Privacy in the Information Age (NYU Press 2004) and his treatise on Information Privacy Law with Paul M. Schwartz of the Berkeley School of Law (Aspen Publishing, 2d ed. 2006). But with Understanding Privacy, Solove has now elevated himself to that rarefied air of “people worth watching” in the cyberlaw field; an intellectual — like Lawrence Lessig or Jonathan Zittrain — whose every publication becomes something of an event in the field to which all eyes turn upon release.
Like those other intellectuals, however, my respect for their stature should not be confused with agreement with their positions. In fact, my disagreements with Lessig and Zittrain are frequently on display here and, we have been critical of Solove here in the past as well. [Here’s Jim Harper’s review of Solove’s last book, with which I am in wholehearted agreement.] In a similar vein, although I greatly appreciate what Prof. Solove attempts to accomplish in Understanding Privacy — and I am sure it will change the way we conceptualize and debate privacy policy in the future — I found his approach and conclusions highly problematic.
Continue reading →

 The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.