Shane Greenstein, Kellogg Chair in Information Technology at Northwestern’s Kellogg School of Management, discusses his recent paper, Collective Intelligence and Neutral Point of View: The Case of Wikipedia , coauthored by Harvard assistant professor Feng Zhu. Greenstein and Zhu’s paper takes a look at whether Linus’ Law applies to Wikipedia articles. Do Wikipedia articles have a slant or bias? If so, how can we measure it? And, do articles become less biased over time, as more contributors become involved? Greenstein explains his findings.
Download
Related Links
Patrick Ruffini, political strategist, author, and President of Engage, a digital agency in Washington, DC, discusses his latest book with coauthors David Segal and David Moon: Hacking Politics: How Geeks, Progressives, the Tea Party, Gamers, Anarchists, and Suits Teamed Up to Defeat SOPA and Save the Internet. Ruffini covers the history behind SOPA, its implications for Internet freedom, the “Internet blackout” in January of 2012, and how the threat of SOPA united activists, technology companies, and the broader Internet community.
Download
Related Links
In my Cato paper, “Publication Practices for Transparent Government,” I talked about the data practices that will produce more transparent government. The government can and should improve the way it provides information about its deliberations, management, and results.
“But transparency is not an automatic or instant result of following these good practices,” I wrote, “and it is not just the form and formats of data.”
It turns on the capacity of the society to interact with the data and make use of it. American society will take some time to make use of more transparent data once better practices are in place. There are already thriving communities of researchers, journalists, and software developers using unofficial repositories of government data. If they can do good work with incomplete and imperfect data, they will do even better work with rich, complete data issued promptly by authoritative sources.
We’re not just sitting around waiting for that to happen. Continue reading →
Very cool little video here by Jess3 documenting Internet growth and activity. Ironically, Berin sent it to me as Adam Marcus and I were updating the lengthy list of Net & online media stats you’ll find down below. Many of the stats we were compiling are shown in the video. Enjoy!
http://vimeo.com/moogaloop.swf?clip_id=9641036&server=vimeo.com&show_title=1&show_byline=1&show_portrait=1&color=ffffff&fullscreen=1
- 1.73 billion Internet users worldwide as of Sept 2009; an 18% increase from the previous year.
[1]
- 81.8 million .COM domain names at the end of 2009; 12.3 million .NET names & 7.8 million .ORG names.
[2]
- 234 million websites as of Dec 2009; 47 million were added in 2009.
[3] In 2006, Internet users in the United States viewed an average of 120.5 Web pages each day.
[4]
- There are roughly 26 million blogs on the Internet
[5] and even back in 2007, there were over 1.5 million new blog posts every day (17 posts per second).
[6] Continue reading →
Over at Silicon Alley Insider, Gregory Galant has a wonderful post about “18 Awesome Tech Things We Didn’t Have 10 Years Ago.” It serves as another great example of the amazing technological progress we have witnessed over the past decade. He’s asking people for suggestions for what else should be on the list, so head over there and let him know. Seems like wi-fi technologies should be on there somehow. FiOS deserves a shout-out, too. And where’s Firefox & Chrome? Also, I’ll put in a special word for some amazing new home theater technologies: high-def flat-screens and projectors; media servers & Windows Media Center; BluRay; and 3 incredible gaming / media consoles (Wii, PS3, & XBox). Anyway, here’s Galant’s list:
Wikipedia
Gmail
Facebook
YouTube
Twitter
AdWords
Amazon AWS
RSS (started in ‘99 but didn’t catch on till the ’00s)
Meetup
iPod
Google Maps
Podcasts
Mint
Skype/VOIP
iPhone
Google Docs
Creative Commons
Flickr
The Internet is massive. That’s the ‘no-duh’ statement of the year, right? But seriously, the sheer volume of transactions (both economic and non-economic) is simply staggering. Consider a few factoids to give you a flavor of just how much is going on out there:
- In 2006, Internet users in the United States viewed an average of 120.5 Web pages each day.
- There are over 1.4 million new blog posts every day.
- Social networking giant Facebook reports that each month, its over 300 million users upload more than 2 billion photos, 14 million videos, and create over 3 million events. More than 2 billion pieces of content (web links, news stories, blog posts, notes, photos, etc.) are shared each week. There are also roughly 45 million active user groups on the site.
- YouTube reports that 20 hours of video are uploaded to the site every minute.
- Amazon reported that on December 15, 2008, 6.3 million items were ordered worldwide, a rate of 72.9 items per second.
- Every six weeks, there are 10 million edits made to Wikipedia.
Now, let’s think about how some of our lawmakers and media personalities talk about the Internet. If we were to judge the Internet based upon the daily headlines in various media outlets or from the titles of various Congressional or regulatory agency hearings, then we’d be led to believe that the Internet is a scary, dangerous place. That ‘s especially the case when it comes to concerns about online privacy and child safety. Everywhere you turn there’s a bogeyman story about the supposed dangers of cyberspace.
But let’s go back to the numbers. While I certainly understand the concerns many folks have about their personal privacy or their child’s safety online, the fact is
the vast majority of online transactions that take place online each and every second of the day are of an entirely harmless, even socially beneficial nature. I refer to this disconnect as the “problem of proportionality” in debates about online safety and privacy. People are not just making mountains out of molehills, in many cases they are just making the molehills up or blowing them massively out of proportion. Continue reading →
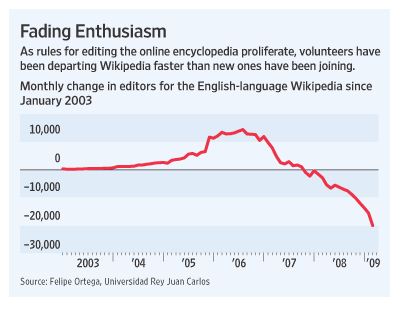 There was a very interesting front-page article in the Wall Street Journal yesterday by Julia Angwin and Geoffrey Fowler wondering whether Wikipedia, the wildly popular online encyclopedia, was dying because of new posting guidelines which have apparently led to a drop off in the number of volunteers contributing to the site. In their article (“Volunteers Log Off as Wikipedia Ages“), Angwin and Fowler note that:
There was a very interesting front-page article in the Wall Street Journal yesterday by Julia Angwin and Geoffrey Fowler wondering whether Wikipedia, the wildly popular online encyclopedia, was dying because of new posting guidelines which have apparently led to a drop off in the number of volunteers contributing to the site. In their article (“Volunteers Log Off as Wikipedia Ages“), Angwin and Fowler note that:
In the first three months of 2009, the English-language Wikipedia suffered a net loss of more than 49,000 editors, compared to a net loss of 4,900 during the same period a year earlier, according to Spanish researcher Felipe Ortega, who analyzed Wikipedia’s data on the editing histories of its more than three million active contributors in 10 languages. Eight years after Wikipedia began with a goal to provide everyone in the world free access to “the sum of all human knowledge,” the declines in participation have raised questions about the encyclopedia’s ability to continue expanding its breadth and improving its accuracy. Errors and deliberate insertions of false information by vandals have undermined its reliability.
The article suggests that new posting and editing guidelines may have something to do with the drop:
But as it matures, Wikipedia, one of the world’s largest crowdsourcing initiatives, is becoming less freewheeling and more like the organizations it set out to replace. Today, its rules are spelled out across hundreds of Web pages. Increasingly, newcomers who try to edit are informed that they have unwittingly broken a rule — and find their edits deleted, according to a study by researchers at Xerox Corp. “People generally have this idea that the wisdom of crowds is a pixie dust that you sprinkle on a system and magical things happen,” says Aniket Kittur, an assistant professor of human-computer interaction at Carnegie Mellon University who has studied Wikipedia and other large online community projects. “Yet the more people you throw at a problem, the more difficulty you are going to have with coordinating those people. It’s too many cooks in the kitchen.”
Let’s say it’s true that the new guidelines have resulted in fewer people contributing. Is that that automatically a bad thing? I suppose it depends on other variables that are harder to measure. Namely, quality metrics. This is where every discussion about Wikipedia gets sticky. Continue reading →
Cory Doctorow has called for a Wikipedia-style effort to build an open source, non-profit search engine. From his column in The Guardian:
What’s more, the way that search engines determine the ranking and relevance of any given website has become more critical than the editorial berth at the New York Times combined with the chief spots at the major TV networks. Good search engine placement is make-or-break advertising. It’s ideological mindshare. It’s relevance…
It’s a terrible idea to vest this much power with one company, even one as fun, user-centered and technologically excellent as Google. It’s too much power for a handful of companies to wield.
The question of what we can and can’t see when we go hunting for answers demands a transparent, participatory solution. There’s no dictator benevolent enough to entrust with the power to determine our political, commercial, social and ideological agenda. This is one for The People.
Put that way, it’s obvious: if search engines set the public agenda, they should be public.
He goes on to claim that “Google’s algorithms are editorial decisions.” For Doctorow, this is an outrage: “so much editorial power is better vested in big, transparent, public entities than a few giant private concerns.”
I wish Doctorow well in his effort to crowdsource a Google-killer, but I’m more than a little skeptical that anyone would actually want to use his search engine of The People. My guess is that, like most things produced in the name of “The People” (Soviet toilet paper comes to mind), it will probably won’t be much fun to use, and will likely chafe noticeably. (For the record, I love and regularly use Wikipedia; I just don’t think that model is unlikely to produce a particularly useful search engine. As Doctorow himself has noted of Google, “they make incredibly awesome search tools.”)
But I’m glad to see that Doctorow has conceded an important point of constitutional law:
The First Amendment protects the editorial discretion of search engines, like all private companies, to decide what to content to communicate. For a newspaper, that means deciding which articles or editorials to run. For a library or bookstore, it means which books to carry. For search engines, it means how to write their search algorithims. Continue reading →
As Berin mentioned last week, we have a new paper out on proposals to expand the Children’s Online Privacy Protection Act (COPPA) of 1998. We generically refer to those COPPA-expansion efforts as “COPPA 2.0.” Hence, the title of our paper: “COPPA 2.0: The New Battle over Privacy, Age Verification, Online Safety & Free Speech.” To recap what Berin already noted, in the name of improving online child safety, some legislators and state attorneys general (AGs) are advocating the expansion of COPPA’s “verifiable parental consent” model of age verification before certain sites or services may collect, or enable the sharing of, personal information for children.
Unlike “COPPA 1.0,” however, which only applied to children under the age of 13, “COPPA 2.0” would apply to all minors up to age 17. Moreover, the range of sites covered by the new law would generally be expanded to include just about any site or service with social networking functionality.
Since Berin has already summarized our general concerns with efforts to expand COPPA’s “verifiable parental consent” online age verification system to cover more online users and sites, I thought I would focus here on what I believe will be the most controversial (and important) part of our paper — our discussion about how COPPA 2.0 affects the speech rights of both adults
and adolescents.
Continue reading →
My problem with what Nick Carr is saying about Wikipedia here — as well as in his book The Big Switch — is that he always seems to assume that Wikipedia constitutes the totality of most searches for information online. I suppose it does for some people, but I have a hard time accepting the argument that everyone’s search for enlightenment ends there, even if Wikipedia does rank high in many search results today.
For me, Wikipedia is just a launch pad; a great starting point in the search for truth. I take much of what I read on Wikipedia with a large grain of salt, however, because I know not every entry is as trustworthy as others, and entries could change at any moment. But that’s true of much of what one finds online! If one adopts a sort of caveat emptor attitude toward Wikipedia, and then uses it to seek out truth from alternative sources found in each entry, or from other searches, then were is the harm? Only if one could show that the search for truth ends with Wikipedia would I be as concerned as Carr and other Internet pessimists and Wikipedia critics (like Lee Siegel and Andrew Keen). But I just don’t believe that is the case.
Moreover, it is impossible for me to believe that we have fewer authoritative sources of information at our disposal today than we did in the past. Continue reading →

 The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.
The Technology Liberation Front is the tech policy blog dedicated to keeping politicians' hands off the 'net and everything else related to technology.